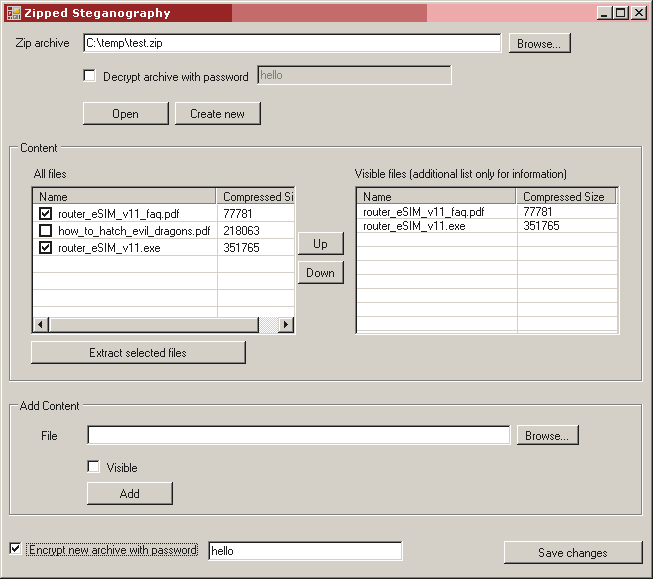
Ein ZIP-Archiv besteht aus lokalen Dateien, von denen jede einen lokalen Header besitzt. Am Ende des Archivs befindet sich das Central Directory, in dem Verweise auf alle Dateien aufgelistet werden. Das zentrale Verzeichnis beschleunigt die Suche nach einer bestimmten Datei im Archiv. Wenn eine Archivierungswerkzeug wie WinZip oder FilZip ein Archiv öffnet, liest es zuerst das zentrale Verzeichnis. Erst wenn eine lokale Datei extrahiert werden soll, wird aus dem Verzeichnis der Byte-Offset gelesen, der die Stelle im Archiv angibt, an der die Datei steht; damit kann die lokale Datei gelesen und dekomprimiert werden. Was nicht im Verzeichnis aufgelistst steht, wird von der ZIP-Anwendung nicht angezeigt.
Oft enthalten ZIP-Archive sehr viele Einzeldateien. Jede davon hat zwei Größenangaben: Komprimierte und unkomprimierte Dateigröße. Aber hast du jemals ausgerechnet, ob die Summe der komprimierten Dateigrößen sich der Größe des Archivs auf der Festplatte annähert? Selbst wenn wir das ausprobieren würden, gäbe es immer eine gewisse Differenz, da auch Central Directory und lokale Header etwas Speicher belegen. Deshalb werden ein paar zusätzliche Bytes - zum Beispiel komprimierte Textdateien - nicht durch Zufall entdeckt werden.
Dieser Artikel verwendet Code aus ICSharpCode’s SharpZipLib.
Dieses Archiv ist sauber, jede gezippte Datei hat ein Gegenstück im zentralen Verzeichnis.

Schau dir dieses Archiv genauer an: Welche ZIP-Anwendung würde die dritte Datei anzeigen? Das Textdokument ist aus dem Inhaltsverzeichnis ausgeblendet.
Um teilweise unsichtbare Archive zu erzeugen, sind nur drei Schritte nötig:
Das erste Problem wurde bereits von ICSharpCode gelöst. Die GPL-lizenzierte Bibliothek SharpZipLib lässt sich problemlos der Projektmappe hinzufügen, mit den Klassen ZipOutputStream und ZipEntry werden Einträge ins Archiv geschrieben. Der Verzeichnis-Eintrag wird für jeden ZipEntry automatisch erstellt.
private void ZipFiles(string destinationFileName, StringCollection sourceFiles)
{
// Archiv zum Schreiben öffnen
FileStream outputFileStream = new FileStream(destinationFileName, FileMode.Create);
ZipOutputStream zipStream = new ZipOutputStream(outputFileStream);
foreach(string sourceFileName in sourceFiles)
{
// Header für eine Datei füllen
inputStream = new FileStream(sourceFileName, FileMode.Open);
zipEntry = new ZipEntry(Path.GetFileName(sourceFileName));
zipEntry.CompressionMethod = CompressionMethod.Deflated;
zipStream.PutNextEntry(zipEntry);
// Inhalt der Datei hinzufügen
byte[] buffer = new byte[4096];
int countBytesRead;
while ((countBytesRead = inputStream.Read(buffer, 0, buffer.Length)) > 0)
{
zipStream.Write(buffer, 0, countBytesRead);
}
// Datei schließen und Verzeichnis-Eintrag schreiben
inputStream.Close();
zipStream.CloseEntry();
}
zipStream.Finish();
zipStream.Close();
}
Wie lässt wir nun der Eintrag im Central Directory vermeiden? SharpZipLib erzeugt das Verzeichnis in ZipOutputStream.Finish(). Dort können wir die Dateien abfangen, die versteckt bleiben sollen. Um zwischen sichtbaren und unsichtaren Dateien zu unterscheiden, habe ich der Klasse ZipEntry eine neue Eigenschaft IsVisible angehängt. Diese in ZipOutputStream.Finish() abzufragen, ist eine Änderung von nur wenigen Zeilen.
namespace ICSharpCode.SharpZipLib.Zip
{
[...]
public class ZipOutputStream : DeflaterOutputStream
{
[...]
public override void Finish()
{
if (entries == null) {
return;
}
if (curEntry != null) {
CloseEntry();
}
int numEntries = 0;
int sizeEntries = 0;
foreach (ZipEntry entry in entries)
{
if (entry.IsVisible) //CJ: List only visible entries
{
[...]
// write the directory item for the zip entry
[...]
}
}
}
}
[...]
}
Mit diesen kleinen Anpassungen ist die Bibliothek in der Lage, lokale Dateien vor dem zentralen Verezichnis zu verbergen. Damit beginnt die eigentliche Heruasforderung: Wir müssen unsere Dateien wiederfinden!
SharpZipLib enthält die Klasse ZipFile, um Archive zu lesen und einzelne Dateien zu dekomprimieren. Sie verlässt sich voll und ganz auf Verzeichnis-Einträge: ZipFile.GetInputStream() nimmt einen ZipEntry oder dessen Index an und liest den Inhalt der lokalen Datei am darin verzeichneten Offset. Da unsichtbare Dateien keinen solchen Eintrag haben, muss auch ZipFile angepasst und um zwei Methoden erweitert werden.
Bevor wir unsichtbare Dateien extrahieren können, brauchen wir ein vollständiges Inhaltsverzeichnis mit allen gezippten Dateien, egal ob sie im Central Directory stehen oder nicht. Da jedes Archiv mindestens eine sichtbare Datei enthalten sollte (sonst wäre zu offensichtlich, dass etwas nicht stimmt), habe ich die erste Datei im zentralen Verzeichnis als Ankerpunkt festgelegt. Am Anfang der ersten “offiziellen” Datei werden wir ins Archiv einsteigen und und durch die folgenden Header voran hangeln. So werdne wir an allen Dateien vorbei kommen, die tatsächlich vorhanden sind. Die neue Methode HasSuccessor(ZipEntry zipEntry) findet das Ende eines angegebenen ZIP-Eintrags und schaut im Stream nach, was dahinter folgt.
/// <summary>
/// Checks the file stream after the given zip entry for another one.
/// </summary>
/// <param name="entryIndex">The index of a zip entry.</param>
/// <returns>true: there are more entries after this one. false: this is the last entry.</returns>
public bool HasSuccessor(ZipEntry zipEntry)
{
if (entries == null)
{
throw new InvalidOperationException("ZipFile is closed");
}
//beginning of the preceeding zip entry
long startPredecessor = CheckLocalHeader(zipEntry);
//end of the preceeding zip entry
long endPredecessor = startPredecessor + zipEntry.CompressedSize;
//get a stream for whatever follows the zip entry
Stream stream = new PartialInputStream(baseStream, endPredecessor, ZipConstants.LOCHDR);
//read what may be a local file header
int localHeaderStart = ReadLeInt(stream);
//is it the beginning of another local file?
return (localHeaderStart == ZipConstants.LOCSIG);
}
Wenn HasSuccessor einen lokalen Header erkannt hat, soll dieser gelesen und anschließend nach dem nächsten gesucht werden. Die meisten Header dürften bereits aus dem Central Directory bekannt sein, aber die für uns interessaten sind neu. Die Unterscheidung fällt leicht, denn bekannte Einträge besitzen die Eigenschaft ZipFileIndex, welche den jeweiligen Index im Verzeichnis angibt. Ist dieser Index -1, so kann es nur eine versteckte Datei sein. Das bedeutet, dieser Header muss gelesen werden. Andernfalls kann einfach der vorhandene Verzeichniseintrag verwendet werden.
/// <summary>
/// Reads the ZipEntry of a file, which has no zip entry.
/// </summary>
/// <param name="entryIndex">The index of the preceeding zip entry.</param>
/// <returns>
/// An input stream.
/// </returns>
/// <exception cref="InvalidOperationException">
/// The ZipFile has already been closed
/// </exception>
/// <exception cref="ICSharpCode.SharpZipLib.Zip.ZipException">
/// The compression method for the entry is unknown
/// </exception>
/// <exception cref="IndexOutOfRangeException">
/// The entry is not found in the ZipFile
/// </exception>
public ZipEntry GetAttachedEntry(ZipEntry predecessor)
{
if (entries == null)
{
throw new InvalidOperationException("ZipFile is closed");
}
//beginning of the preceeding zip entry
long startPredecessor = CheckLocalHeader(predecessor);
//end of the preceeding zip entry
long endPredecessor = startPredecessor + predecessor.CompressedSize;
//get a stream for the undocumented local file
Stream stream = new PartialInputStream(baseStream, endPredecessor, ZipConstants.LOCHDR);
//read local file header
int localHeaderStart = ReadLeInt(stream);
if (localHeaderStart != ZipConstants.LOCSIG)
{
throw new InvalidOperationException("Invalid local file header");
}
int version = ReadLeShort(stream);
int flags = ReadLeShort(stream);
int method = ReadLeShort(stream);
int dosTime = ReadLeInt(stream);
int crc = ReadLeInt(stream);
int compressedSize = ReadLeInt(stream);
int uncompressedSize = ReadLeInt(stream);
int nameLength = ReadLeShort(stream);
int extraLength = ReadLeShort(stream);
//get a stream only for file name
long offset = endPredecessor + ZipConstants.LOCHDR;
Stream fileInfoStream = new PartialInputStream(baseStream, offset, nameLength);
byte[] buffer = new byte[nameLength];
fileInfoStream.Read(buffer, 0, nameLength);
string name = ZipConstants.ConvertToString(buffer);
int indexFromDirectoy = FindEntry(name, false);
ZipEntry zipEntry;
if (indexFromDirectoy < 0)
{
zipEntry = new ZipEntry(name, version);
zipEntry.CompressedSize = compressedSize;
zipEntry.CompressionMethod = (CompressionMethod)method;
zipEntry.Crc = crc;
zipEntry.DosTime = dosTime;
zipEntry.Flags = flags;
zipEntry.IsVisible = false;
zipEntry.Offset = (int)endPredecessor;
zipEntry.Size = uncompressedSize;
zipEntry.IsVisible = false;
zipEntry.ZipFileIndex = -1;
}
else
{
zipEntry = entries[indexFromDirectoy];
zipEntry.IsVisible = true;
}
return zipEntry;
}
Damit haben wir alle Methoden beisammen, um ein echtes Verzeichnis des Archivs aufzubauen. So wird eine eine ZIP-Datei geöffnet und durchsucht:
// Archiv öffnen
ZipFile zipFile = new ZipFile(txtZipFileName.Text);
// Von der ersten Datei aus alle folgenden finden
ZipEntry zipEntry = zipFile[0];
AddListViewItem(zipEntry, lvAll);
int entryIndex = 0;
while (zipFile.HasSuccessor(zipEntry))
{
zipEntry = zipFile.GetAttachedEntry(zipEntry);
AddListViewItem(zipEntry, lvAll);
entryIndex++;
}
Obwohl wir nun die vollständige ZipEntry-Auslistung kennen, können wir noch keine unsichtbaren Dateien extrahieren. Das liegt daran, dass ZipFile.GetInputStream() versucht, den Verzeichnisindex zu verwenden, der natürlich nur mit dem Platzhalter -1 gefüllt ist. Aber was wir praktisch nur brauchen, um den Inhalt einer Datei zu lesen, ist ihr Offset im Archiv-Stream: Haben wir die Eigenschaft Offset der ZipEntry-Objekte nicht schon beim Lesen gefüllt? GetInputStream(ZipEntry entry) weiß nur noch nichts davon. Aber das lässt sich ändern, indem ZipFile.GetInputStream() ersetzt und aufgeräumt wird .
public Stream GetInputStream(ZipEntry entry)
{
if (entries == null) {
throw new InvalidOperationException("ZipFile has closed");
}
/*
* Original-Methode
* Wird ersetzt, um "invisible" Einträge zu unterstützen
*
int index = entry.ZipFileIndex;
if (index < 0 || index >= entries.Length || entries[index].Name != entry.Name) {
index = FindEntry(entry.Name, true);
if (index < 0) {
throw new IndexOutOfRangeException();
}
}
return GetInputStream(index);
*/
if (entries == null)
{
throw new InvalidOperationException("ZipFile is closed");
}
// Nicht nach ZipFileIndex suchen! I don't know why it was originally
// implemented that way, but we know the data offset and indices are not
// necessary. There are no indices for the invisible files.
long start = CheckLocalHeader(entry);
// Kopiert aus GetInputStream(int entryIndex)
CompressionMethod method = entry.CompressionMethod;
Stream istr = new PartialInputStream(baseStream, start, entry.CompressedSize);
if (entry.IsCrypted == true)
{
istr = CreateAndInitDecryptionStream(istr, entry);
if (istr == null)
{
throw new ZipException("Unable to decrypt this entry");
}
}
switch (method)
{
case CompressionMethod.Stored:
return istr;
case CompressionMethod.Deflated:
return new InflaterInputStream(istr, new Inflater(true));
default:
throw new ZipException("Unsupported compression method " + method);
}
}
Fertig! Jetzt sind wir in der Lage, alle Dateien zu entpacken, inklusive unserer Geisterdateien. Die so gesammelten Dateien können nun gelesen werden.
private void UnZipFiles(string destinationDirectoryName)
{
ZipFile zipFile = new ZipFile(txtZipFileName.Text);
if (chkDecrypt.Checked)
{
zipFile.Password = txtOpenPassword.Text;
}
foreach (ListViewItem viewItem in lvAll.SelectedItems)
{
ZipEntry zipEntry = viewItem.Tag as ZipEntry;
if (zipEntry != null)
{
Stream inputStream = zipFile.GetInputStream(zipEntry);
FileStream fileStream = new FileStream(
Path.Combine(destinationDirectoryName, zipEntry.Name),
FileMode.Create);
CopyStream(inputStream, fileStream);
fileStream.Close();
inputStream.Close();
}
}
zipFile.Close();
}
Jetzt gibt es für uns keinen großen Unterschied mehr zwischen sichtaren und versteckten ZIP-Einträgen. Unsere angepasste Bibliothek behandelt beide Varianten gleich gut: Ist die Eigenschaft ZipEntry.IsVisible vor dem Komprimieren auf false gesetzt, wird die Datei vor dem Central Directory versteckt - aber Anwendungen, die diese angepasste Version von SharpZipLib und HasSuccessor/GetAttachedEntry anstelle des Verzeichnis-Indexers verwenden, können sie dennoch finden und entpacken.
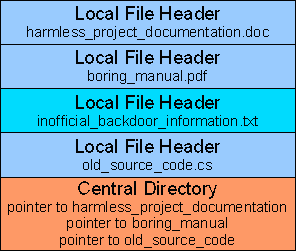
Die Demo-Anwendung kann neue ZIP-Archive erstellen oder vorhandene bearbeiten. Man kann sichtbare und unsichtbare Dateien hinzufügen/löschen, oder auch ein Archiv mit einem Kennwort versehen. Von Letzterem rate ich allerdings ab, da versteckte Dateien bei mehrmaligem Ver- und Entschlüsseln verloren gehen können. Im Bild unten wird eine unsichtbare Datei in ein vorhandenes Archiv eingefügt. Sichtbare Einträge stehen zusätzlich in der rechten Box, als Vorschau darauf, wie ein normales ZIP-Werkzeug den Inhalt anzeigen wird.
Die Checkboxes in der linken Liste legen fest, ob eine Datei im Central Directory verzeichnet wird oder nicht. Um eine Datei vor dem Inhaltsverzeichnis zu verbergen, entferne einfach den Haken. Mit “Delete” wird die markierte Datei aus dem Archiv gelöscht. “Extract selected files” entpackt jede beliebige Datei, versteckte und sichtbare werden genau gleich behandelt.
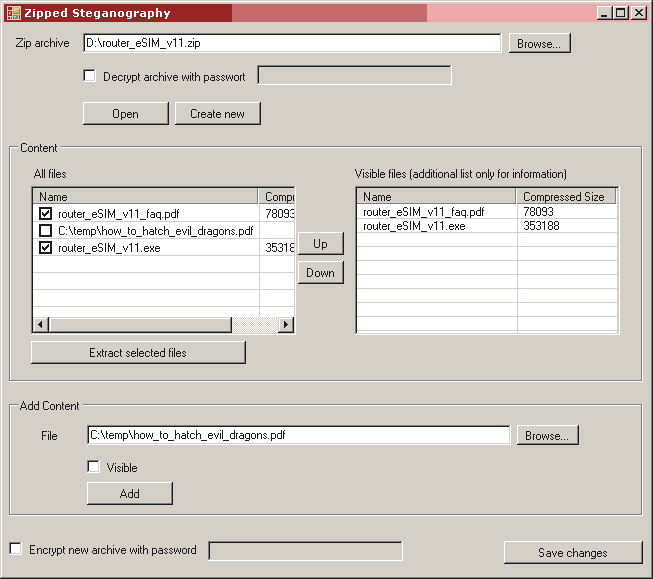
“Save changes” fragt nach einem neuen Dateinamen. Alle Dateien aus dem Archiv und die neu hinzugefügten werden komprimiert und ins neue Archiv eingefügt. Anschließend öffnet die Demo das neue Archiv, so dass es weiter bearbeitet werden kann.
Auf diesem Bild wurde das neue Archiv mit einer versteckten und zwei sichtbaren Dateien gerade gespeichert und wird als Nächstes mit dem Kennwort “hello” verschlüsselt.
VORSICHT: Wenn möglich solltest Du Verschlüsselung vermeiden oder zuerst ein unverschlüsseltes Archiv bearbeiten/speichern und die Verschlüsselung im allerletzten Schritt hinzufügen. Manchmal funktioniert es, manchmal verliert man alle versteckten Dateien außer der ersten. :-(
Gewöhnlich geht die erste Verschlüsselung gut, aber erneutes Speichern des bereits verschlüsselten Archivs macht die lokalen Header unverfolgbar. Besonders wenn es mehr als eine unsichtbare Datei im Archiv gibt, probiere das Verschlüsseln bitte erst, wenn alles schon sicher gespeichert ist. </div>